Data structures for proteomics
Most discussions of proteomics infrastructure focus on the moving parts: the instruments, the search engine, the pipeline orchestrator, the dashboard. The part that quietly determines what the whole stack is capable of — the shape of the data underneath — gets less attention than it deserves.
That is the wrong order of priorities. The data model decides which questions are cheap to answer, which are expensive, and which are not answerable at all. By the time a team realises that an obvious question is unanswerable, the cost of changing the schema has compounded: every dashboard, every notebook, every report and every downstream warehouse table has to move with it. We have done a number of these migrations. They are never cheap and rarely fun.
The good news is that most of the painful redesigns we have seen could have been avoided with a handful of decisions at the start. What follows is a sketch of the model we keep coming back to, and the lessons that we have collected the hard way in arriving at it.
The shape of the data
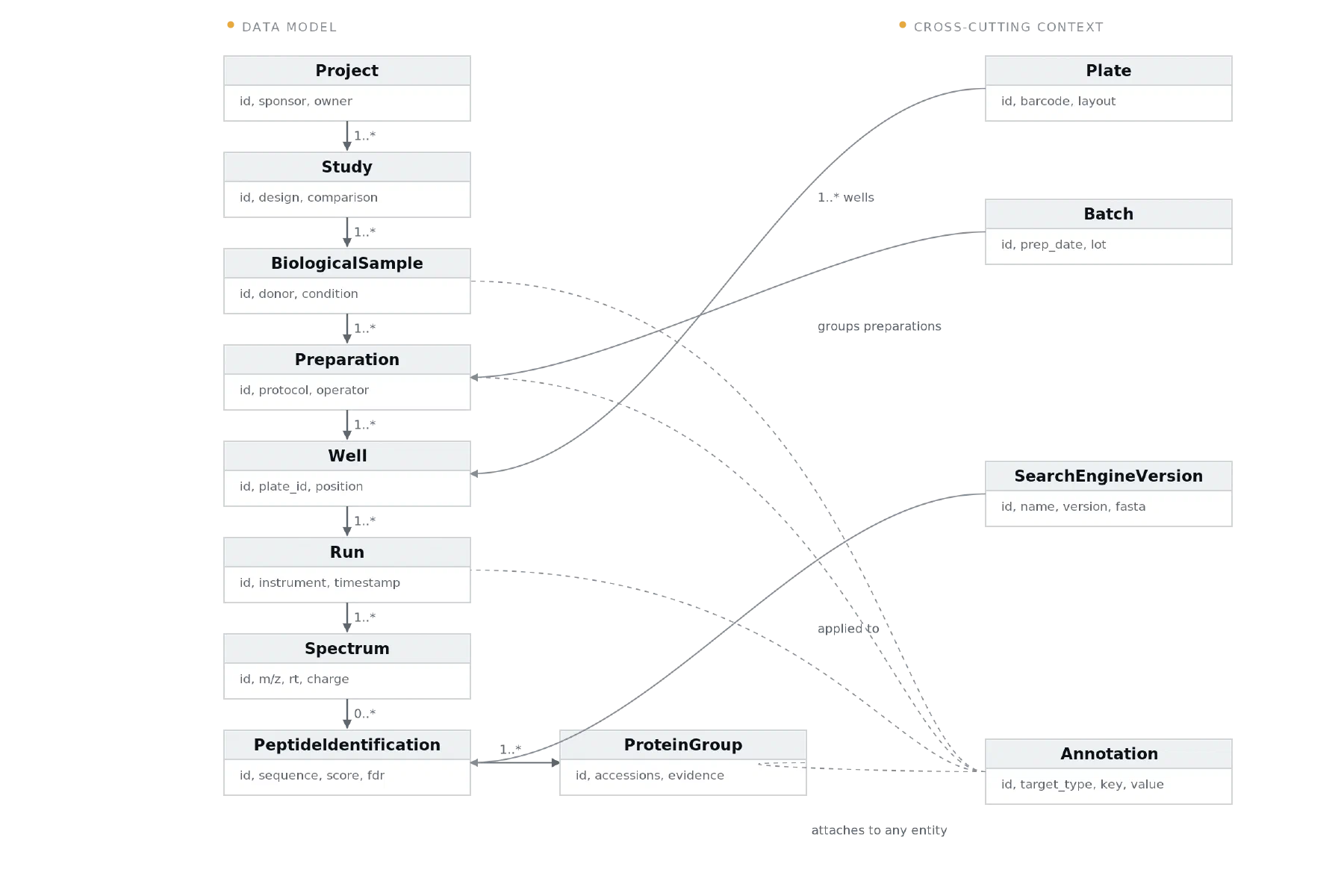
The diagram above sketches the data model we keep coming back to. It is not glamorous, but it is more articulate than the flat tables it usually replaces. Each fan-out on the main spine — a study has many biological samples, a sample has many preparations, a preparation has many runs — is a question waiting to be asked. Collapse any of them and the question dies with the collapse.
The entities on the right are the part that practitioners often underweight. Batch, plate, software version, annotation: these are not housekeeping fields, they are the entities that explain the spine. Without them, the spine is just an audit trail; with them, it is a basis for reasoning about why a result looks the way it does.
Six lessons
1. Separate the biology from the preparation from the injection.
The single most common simplification we see is one row per “sample” — where “sample” silently conflates the biological specimen, its preparation, and the LC-MS run that measured it. The moment a single donor is digested twice with different protocols, or a single preparation is injected three times for technical replication, the model fails. The fix is small in retrospect and almost impossible to retrofit: three entities, three foreign keys, three places to attach metadata.
2. Plate and batch are first-class entities, not metadata columns.
Adding a plate_id column to a sample table feels harmless. It is — until the day someone asks “is plate 7 the reason this comparison looks off?” and there is nowhere to attach the plate’s preparation date, its operator, its layout, the QC sample it ran alongside. Treat plates and batches as their own tables from day one. The investment is trivial; the question “is this a batch effect?” becomes a join instead of a forensic exercise.
3. Replicate type must be explicit, not implicit.
Technical and biological replicates require different statistical handling, and downstream code that treats them identically will produce confidently wrong results. A schema that records replicate_number = 1, 2, 3 without saying what kind of replicate it is forces every analysis to re-derive that information from naming conventions, comments, or institutional memory. Make it a column on the right entity, with a controlled vocabulary, and never look back.
4. The peptide identification is not the peptide — capture the interpretation.
A peptide identification is a function of the spectrum and of the search engine, its version, the FASTA database it was run against, the modifications considered, the score cutoff applied. None of that is intrinsic to the peptide; all of it determines whether the identification exists. Pin it as a separate SearchEngineVersion entity (or whatever name fits your team’s vocabulary) and foreign-key into it from every identification. The day someone re-searches with a new database and you want to compare to last year’s results, you will not be guessing what changed.
5. Annotations are append-only, polymorphic and timestamped.
Every team eventually accumulates free-text observations: a note that a sample looked unusual, a flag that a run had a leak, a comment that a protein group is suspected to be a contaminant. If these live as columns scattered across the main tables, they get overwritten, lost in copy-paste, and impossible to audit. A single Annotation table — recording (target_type, target_id, key, value, author, timestamp) — collapses the problem to one shape, makes the audit trail free, and gives the team a place to evolve a controlled vocabulary over time.
6. Pin identifiers by version.
Protein accessions move. UniProt entries get merged, split, deprecated. A pipeline that records “P12345” without recording the database release captures something that may not mean the same thing six months from now. Store the database release alongside the accession on the day the identification is computed. The comparisons that fail silently for want of this discipline are the ones that hurt most — because they look like real biology until they don’t.
Why this is hard to fix later
None of these lessons is technically difficult. The reason they end up as “hard-won” is that the cost of changing a schema scales with the surface area built on top of it. By the time the limitation becomes visible — usually because someone asks a question the model cannot answer — there are typically dashboards, downstream tables, exported Excel files in the hands of scientists, and analyses in flight that have all baked in the original shape. The migration is a coordination problem more than an engineering problem.
Which is why we keep returning to the same principle: model the entities, the relationships and the cardinalities you might need, even when the immediate analysis does not require them. The cost of carrying an entity that turns out to be redundant is low. The cost of inventing an entity once the data has shipped without it is high.
If you are scoping a new proteomics pipeline, or if you are looking at a model you inherited and wondering which of the questions you cannot currently answer are worth fixing, this is exactly the kind of conversation we like. Drop us a line.